Diseño de archivos y base de datos
Elementos básicos del diseño de archivos y base de datos:
1. entidades (entities)
2. campos (fields)
3. records
4. archivos (files)
5. llaves (keys)
1. Entidad – Persona, lugar, objeto u evento para el cual se obtiene y mantiene datos. Ejemplo: Cliente, Orden, Producto, Suplidor.
2. Campo – Atributo o característica de la entidad. Ejemplo: en la entidad Cliente, algunos campos pueden ser Nombre, Apellido, Dirección.
3. Record – Es una colección o grupo de campos que describen un miembro de una entidad. Ejemplo, el record de un cliente, o de un producto.
4. Archivo – Es un grupo de records que contienen datos sobre una entidad en específico. Ejemplo: el archivo de clientes, es archivo de productos, o de empleados.
5. Llave o Key – Es un campo que se usa para localizar, accesar o identificar un record en específico. Hay cuatro tipos de “key”:
a. Primary key – es un campo u combinación de campos que en forma única y mínima identifica un miembro en particular de una entidad. Es único porque no hay dos miembros con el mismo key. Es mínimo porque contiene tan solo la información necesaria para identificar al miembro de la entidad. Si el primary key es una combinación de varios campos se conoce como “multivalue” key.
b. Candidate key – cualquier campo que pueda servir como primary key. Para seleccionar al primary key, se escoge el campo que tenga menos datos y sea más fácil de usar. Cualquier campo que no es un primary key o un candidate key se llama nonkey field.
c. Foreign key – es un cambo en un archivo que debe parear con el valor del primary ley de otro archivo para que se pueda establecer una relación o “link” entre ambos archivos.
d. Secondary key – es un campo u combinación de campos que se puede usa para accesar, record. Los secondary keys no necesitan ser únicos. Ejemplo: nombre del cliente, código postal (zipcode).
Diagrama de relación entre entidades
Una relación es una unión lógica entre entidades basado en cómo interaccionan. Ejemplo: Existe una relación entre Productos y Almacén porque los productos se guardan en un almacén. Un diagrama de relación entre entidades (entity-relationship diagram – ERD) muestra en forma gráfica las relaciones entre las entidades. En el ERD se utiliza un rectángulo y un nombre en singular para representar la entidad. Se utiliza un diamante y un verbo para representar la relación entre las entidades. El ERD NO tiene flechas, porque no muestra flujo de información.

Ejemplo:

Pueden existir tres tipos de relaciones:
1. uno-a-uno (1:1) – existe cuando exactamente un miembro de la segunda entidad se relaciona con un solo miembro de la primera entidad.

2. uno-a-mucho (1:M) – existe cuando un miembro de la primera entidad se puede relacionar con muchos miembros de la segunda entidad, pero cada miembro de la segunda entidad se relaciona tan solo con uno de la primera entidad.
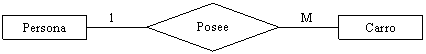
3. mucho-a-mucho (M:N) – existe cuando un miembro de la primera entidad se puede relacionar con muchos miembros de la segunda entidad; y un miembro de la segunda entidad se puede relacionar con muchos miembros de la primera entidad.

Cardinalidad – describe cómo un miembro de una entidad se relaciona con un miembro de otra entidad. Puede ser:
a. Mandatoria – significa que en la relación siempre se requiere al menos un miembro de esa entidad.
b. Opcional – significa que en la relación puede existir uno, varios o ningún miembro de la entidad.
Por ejemplo, un cliente puede tener una, varias o ninguna orden de compra (opcional), pero una orden de compra tiene que ser de un solo cliente (mandatoria). Se utiliza los símbolos llamados “crow’s foot notation” para presentar la cardinalidad:
| | --- uno y solo uno
O --- ninguno
< --- uno o varios



Normalizar:
Es el proceso por el que se identifica y corrige los problemas de diseño de record. Un diseño de record especifica los campos e identifica el key primario, si alguno, para todos los records en un archivo en particular. Se normaliza el record para desarrollar una base de datos simple, flexible y libre de duplicidad de datos. Un record sin normalizar contiene grupos repetitivos, o sea, un solo record tiene varios valores en un mismo campo. El proceso de normalizar se compone de tres fases: primera forma normal, segunda forma normal y tercera forma normal. Mientras más normalizado esté un record, mejor es su diseño.
Primera Forma Normal (1FN) – Un record está en 1FN si no contiene grupos repetitivos. Para llevar un record a 1FN, se expande el key primario para incluir el key del grupo repetitivo, combinando ambos keys para identificar un record en forma única.
Segunda Forma Normal (2FN) – Se usa el concepto de dependencia funcional: un campo X depende funcionalmente de Y si el valor de Y determina el valor de X. Un record está en 2FN si está también en 1FN y todos los campos que no son parte del key primario dependen de todo el key primario.
Tercera Forma Normal (3FN) – Existe si el diseño del record está en 2FN y ningún campo no-key depende de otro campo no-key.
Modelos de Base de Datos
1. Hierarchical Database (Jerárquica) – Los datos se organizan como un organigrama, con records “padres” y records “hijos”. Las relaciones se definen como asociaciones padre-hijo. Tiene como desventajas:
a. Que cada record hijo debe tener tan solo un record padre. Por ejemplo, si el record padre es un consejero, un estudiante sin consejero no puede estar en el sistema.
b. Cambios a la estructura de un record requiere reorganizar la base de datos y modificar los programas.
c. El modelo es muy complejo y complicado para mantener.
2. Network Database – Es un grupo de records arreglados en una relación uno-a-muchos. Un record puede ser miembro de varios grupos sin restricción. Su desventaja es que cualquier cambio a la estructura de datos requiere que se vuelva a crear la base de datos y sea necesario que se compilen nuevamente los programas afectados.
3. Relational Database – Los datos se organizan en tablas o relaciones de dos dimensiones. Una ventaja importante es su simplicidad. Se puede hacer cambios a la base de datos sin tener que reestructurar la base. Es el modelo que predomina en los diseños actuales.
4. Object-Oriented Database – Se enfoca en los datos en vez de en los procesos, usando objetos para así reducir los costos, el desarrollo y el mantenimiento. Muchas veces se usa con estructuras relacionales. Este método es flexible, fácil de mantener y reduce los costos operacionales.